How CoverTree moved rating engine to AWS Lambda in 3 weeks?
Published on Wednesday October 30, 2024
Within Insurtech company tech stack, Rating Engine is one of the crucial components, which needs to combine reliability, maintainability and also performance. At CoverTree we understand those principles and as part of this story, we want to explain why we had to rapidly move our Rating Engine to Amazon Web Services Lambda. The story will cover both decision process, implementation, unexpected obstacles, tweaks and results of the final serverless implementation.

The problem statement
When CoverTree started as a startup there was a need to make a crucial technological decision – whether the core Policy Management System (PAS) should be created from scratch for our needs, or should we use one of the market available solutions. After long analysis the decision was made to use Socotra – the Insurance Platform, which already has implemented all the key components such as Rating, Underwriting, Transaction handling, robust API and more. For the initial growth that was a great decision allowing us to quickly build the whole platform and get to the public – our success story describing the details is available here.
However during our rapid growth in 2023, especially during implementation of our offering within new states we started seeing more issues coming from our initial Rating Engine implementation. Socotra allows for extensive modification to tailor its’ customer needs – for the Rating Engine you are able to write your own custom code in JavaScript. Think of it as a function – black box, which accepts all data for the policy and returns pricing details. From the very beginning of CoverTree we had issues with one main thing – lack of ability to price multiple, editable quotes at once.
CoverTree prepares three (Silver, Gold, Platinum) versions of the Policy, each having different configurations, hence having different prices. In order to fulfill that requirement, we needed to somehow price those three versions of the Policy. Unfortunately lack of concurrent pricing out of the box resulted in us implementing a solution, which called rating engine synchronously. That led to another issue, which was long request times. As we are using AWS AppSync as our main entrypoint, we have a strict, thirty seconds limit until the request times out. For the initial set of States, which had a simple rating algorithm, we were doing fine. However once we moved to bigger states (namely Texas) our requests started to timeout.
First solution found
The search for the solution began. Our first idea was to use some of the Socotra capabilities. We looped through the documentation and found the ability to run stateless pricing within Socotra itself. The article and solution seemed promising – we will be able to concurrently run three requests from our AWS Lambda handler, which handles GraphQL mutation. However reality wasn’t that good, after looking into Cloudwatch logs of our implementation we have seen something like this (of course data was redacted):
14:34:42.236Z INFO Pricing quote, quoteLocator: 1 14:34:42.886Z INFO Pricing quote, quoteLocator: 2 14:34:48.557Z INFO Create new record in dynamo table for quote 1 14:34:52.817Z INFO Create new record in dynamo table for quote 2
Our system was first sending requests to the rating engine asynchronously using Promise.all JavaScript feature and once the response was returned it was adding the Quotes entries to DynamoDB. After a deeper look into the logs, we can see that requests were started roughly at the same time, however the responses are four seconds apart, which led us to think those requests are not handled in a concurrent way – if they were, the responses should come roughly at the same time. Clearly that was a dead end, which created another requirement – we need to somehow move the Rating Engine outside of Socotra.
AWS Lambda to the rescue
As we knew that our rating engine is essentially a single function, which accepts policy and returns the pricing, we decided to use one of the key Amazon Web Service’s services – AWS Lambda. However we needed a way for Socotra to call the moved Rating Engine. Fortunately Socotra has an External Rater feature, which allows us to do external HTTP calls in order to obtain the pricing for the policy. We knew that the clock was ticking – we needed to launch Texas quickly. It meant there was no place for any significant rewrite. Due to our research we were able to clearly outline the requirements of the new system:
- Move the Rating Engine out of Socotra to make it concurrent. Use the External Rater feature for it.
- Make sure the performance of a single request is at least as good as the previous solution.
- Use the current implementation, build only additional blocks, which would allow it to run in on AWS Lambda.
The third requirement was especially important, because we had a seperate team, which was solely responsible for handling the rating code. We didn’t want to change their development habits, nor did we have time for it.
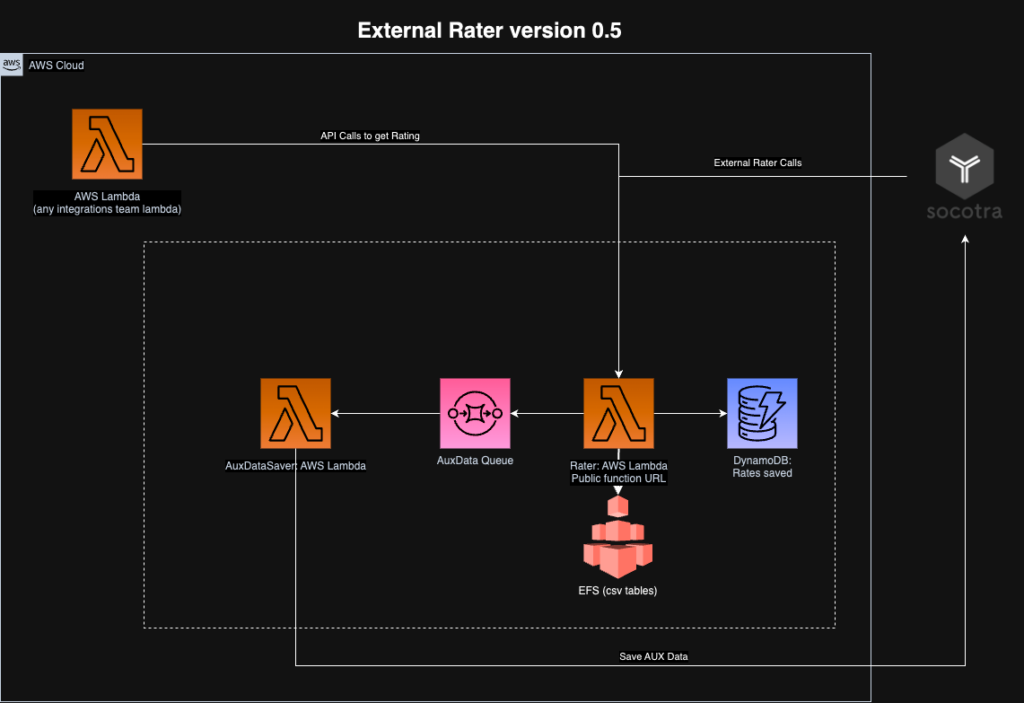
The architecture diagram of AWS solution.
However that led to the first obstacle, which were Plugin Data Fetch, Table Configuration and Auxiliary Data features of Socotra. Those three were used heavily in our rating. First one allows to grab details of various entities related to the Policy (and the Policy itself), second one allows to open Comma Separated Value (CSV) tables and search through them. Auxiliary Data however allows us to save non-structured data, which can be retrieved during and after the rating process. The deep analysis of our rating code resulted in easy solutions – we can just override the socotraApi global object with our implementations of those features, while running the exact same rating code on AWS Lambda.
AWS Lambda code implementation requirements
Fortunately for us, we weren’t really reading any other entities using Data Fetch, we were only getting the priced policy data, so the implementation was very quick. We decided to move those CSV files to Amazon Elastic File System in order to be able to access them really quickly via simple use of fs Node.js standard library.
Auxiliary Data was little a bit more tricky. It was used in various sub-functions of our rater in order to exchange some data between various parts of the rating engine code. However we quickly noticed that we are really grabbing only the data saved within a single rating session. The solution came up – let’s just keep an array of Aux data per rating session and save it to DynamoDB at the end with use of Socotra API. We also decided to use AWS Lambda Function URL as simple a solution for Lambda-to-Socotra exposure.
First results
After two solid days of coding the first solution was finished. The synthetic testing phase began. After sending dozen of pricing requests something seemed very off – the new solution was actually slower in comparison with the Socotra one. At that point we implemented sophisticated tracing with use of AWS Lambda Powertools which allowed us to successfully pinpoint the issue. We have seen that some CSV file opens take upwards of two seconds. That seemed very odd, EFS is really fast. After a deeper look we realised that those reads were unsuccessful – those files haven’t existed. It was an issue deep down in the rating code, which we weren’t allowed to touch. There was only one possible solution – we needed to somehow cache the information about the missing file, in order to not read it again for the current and next rating request.
How breaking the stateless Lambda principle resulted in great performance
I quickly scrambled an easy solution – a simple Map outside of AWS Lambda handler, which would keep an array of entries within a CSV file based on the filename key. As you can clearly see, we broke one of the main serverless principles – the function needs to be stateless. However after a round of thought we have seen that it is not an issue at all. As we are using AWS CDK and the Lambda code deployment is directly tied to CSV files upload we knew that it is impossible to make those two out of sync. Also the solution had an additional great benefit – if the next rating request was passed to the already existing Lambda Execution Environment, which has some CSV files in the Map, it drastically speeds up the response times. To more deeply understand it the Lambda internals behind it, I recommend reading the “Understanding the Lamnbda execution environment lifecycle” article.
The success story results
The whole process of moving our whole Rating code took roughly three weeks. The infrastructure allowed us to do virtually as many rating requests as we wish. The default maximum scaling limit of AWS Lambda is 1000 concurrent execution environments, the number way higher than we needed at the time. Moreover for the more complex states the execution time of the rating process decreased from roughly sixteen seconds to six seconds for cold executions (those without any CSV files cached); and to short of one second for hot ones. None of the original Rating Engine implementation was changed, we only added a “compatibility” layer to run in on AWS Lambda and AWS CDK infrastructure code.
More Articles
February 10, 2025
Usage of AWS CDK Aspects and Lambda Powertools for improved observability
May 8, 2024

